
序 #
之前写过一篇python的领域驱动相关开发的文章,收到同事的称赞,但有些人说我是翻译抄袭的,顺便冷嘲热讽一下。刚好最近公司一些新项目都在往go里面迁移。但收到之前python/PHP影响颇深,思维固化。依然按照原先脚本语言的方式继续往上糊。但是又不知道怎么写好。刚好我负责了一个新的项目。实践一遍DDD。所以写几篇文章分享出来。
我们做错了什么? #
但凡讲DDD的时候,我们会被很多概念吓唬住,比如什么实体、值对象、CQRS 等等,听起来十分高端,十分上档次。但从来没有人说我们为什么这样做。为什么要弄出这么多概念来?存粹为了装逼吗?要搞懂为什么要理解以上概念,我认为更多应该理解我们错在什么地方了,或者我们遇到什么问题了才能从解决问题的角度去理解他并且驾驭它。不会人云亦云。被人牵着鼻子走。
演化 #
首先我们看下传统的MVC,这是我们最熟悉的方式了。
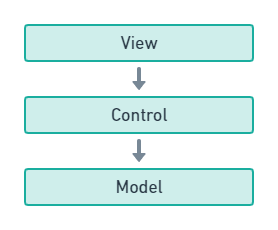
传统的MVC中,View 层代表渲染层一般意义上我们负责构建和渲染HTML,Control控制层负责处理请求和拉取数据并把数据给View层渲染,Model层负责定义我们流转在系统中的各种数据。这么看貌似没什么问题。一般情况下我们一直也是这么做的。但是随着时代的发展,前后端开始分离。也就是说,View层从此不由我们后端负责了。View层交给了我们的前端去做了。于是就形成了这样的结构
后端不再处理如何渲染了,后端实际上只有了,Control和Model,专注于业务逻辑。但现在有问题吗?确实没什么问题。但是对于简单的项目来说,确实够用了。毕竟我们就是从数据库里查查数据,改改数据,然后组织成json之类数据格式返回给前端。类似这样
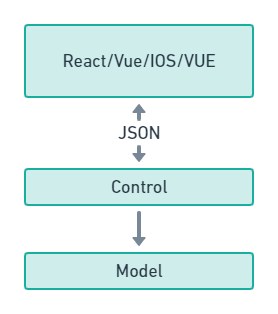
但往往我们的业务并没有那么简单,自从分离后,Control太重了。我们这里经常会做很多事请,除了查询数据库,我们还有验证表单,参数,验证业务逻辑,等等,混乱开始在Control滋生。怎么办?所谓没有什么事情是加一层不能解决的,如果有那就再加一层于是,我们把Control拆分成Action/Service层
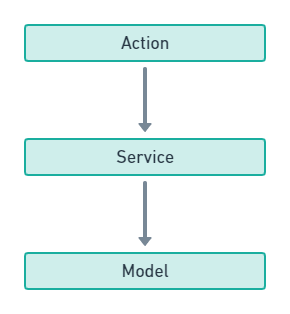
Action层主要负责验证入参及输出,Service负责封装业务逻辑,解决一部分Control膨胀的问题。但问题解决了吗?其实并没有,随着业务发展,service也会越来越膨胀复杂。Service不仅仅控制了数据库的查询,事务,修改,还有整合了各种外部服务,比如RPC,其他业务的Restful API,各类云服务,缓存,消息队列,日志记录,ES搜索引擎等
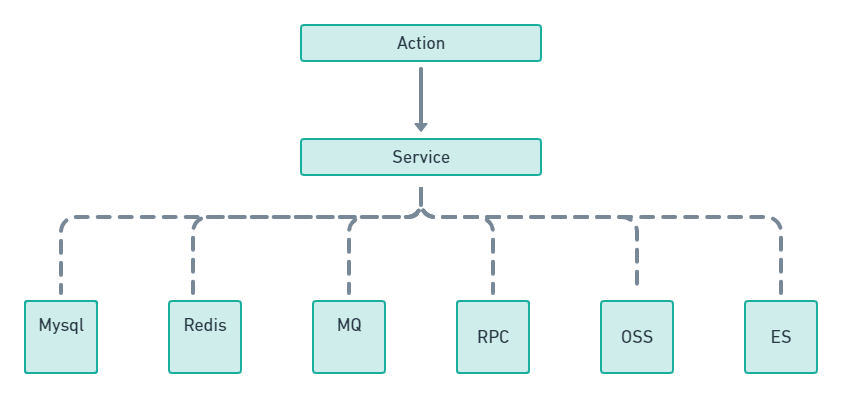
没错,Service开始膨胀,开始不堪重负,他处理了太多细节,复杂度开始失控。随着越来越多的人加入,因为Service包含了部分查询,你团队的有些人开始为了快速开发,Service开始调Service,互相依赖Service]

没错,你的项目慢慢开始出现循环引用,但你没有什么好的办法解决,为了拆掉循环引用,你把部分相同的查询和其他业务基础设施重复实现。一旦发生需求变动,开始形成了多米乐骨牌效应。此时项目质量开是下降,牵一发动全身。每一次需求变动就会导致各种连锁反应。项目经理开始骂街,产品经理开始抱怨。你开始想通过单元测试来勉强维护项目质量。但其实你根本推行不下去。因为你的发现,单元测试要把这些该死的外部服务全部mock掉,但你根本mock不掉。

怎么办 #
知道问题就可以着手解决问题,其实解决此方法的问题,其实很简单,我们只需要遵守两个原则
- 单一职责
- 依赖倒置
听起来很简单,但是怎么实践是个困难的问题。此时我们就需要使用DDD的规范和理论指导去构建我们的应用程序。DDD的概念非常广,我们这里只讨论代码技术层面的问题。不去讨论战略战术的问题。我将会使用buffalo 来做例子
为啥用Buffalo?Gin不香吗?Gorm不香吗? #
在Go语言中,框架不像其他语言那样无所不阔,大多数是对net/http包进行封装。在后续的文章中,你会发现,我们所要解决的问题也跟框架无关,用Buffalo的原因是因为我懒。代码我将会在github上供参考。
安装和构建框架 #
#
上一章我们讲到,我们会使用buffalo 来构建我们的应用程序,首先安装buffalo
$ go get -u -v github.com/gobuffalo/buffalo/buffalo
然后使用他的工具生成我们的项目
$ buffalo new petshop --api --db-type mysql --docker standard
我们可以看到他帮我们生成好的项目结构
.
├── actions #1
├── config
├── database.yml #2
├── Dockerfile
├── fixtures #3
├── go.mod
├── go.sum
├── grifts #4
├── inflections.json
├── locales
├── main.go #5
├── models #6
└── README.md
- action, 也是我们http接口入口
- database.yml, 数据库的配置
- 存放我们测试的数据夹具,在我们进行进程测试时帮我们生成数据使用
- 任务入口,一些后台脚本
- main.go,程序编译入口
这是一个非常简单的MVC的框架,如同我们上章讲到的,我们一般会在这样的基础之上直接进行开发应用程序,开始进行一个面向数据库模式的开发。我们操作着各种各样的数据,然后使用字符串拼接各种各样的sql。用各种查询来维护数据的关系,从来不对数据进行对象建模。一旦项目变大,业务逻辑一旦复杂。我们很难理清这些关系。当面临多人开发的时候。不得不把数据关系的细节一遍又一遍的讲清楚数据的细节。我们称之为事务脚本模式。相反,我们不应该把注意力去放在数据库上,而是放在行为上。用对象去建模我们的数据关系。驱动存储而不是反过来。
随后我们通过领域驱动的方式,一步步来构建我们的应用程序。可能会有些坏的例子,来解释我们为什么这样做,我们先看看我们大概是个什么路子

说白了,从代码层面上讲,领域驱动会用到如下几种模式
- 仓储模式( Repository)
- 领域服务层 ( Service )
- 工作单元模式 (Unit of Work)
- 聚合与聚合根 (Aggregate)
我们一步步通过一个小例子使用上述几个模式来构建我们应用程序。就是一个宠物商店的模型,其实很简单,就是买个猫狗,然后有个后台接口来增加库存什么的。


连接 #
-
Buffalo文档: https://gobuffalo.io/en